Hello, my name is Hrvoje 👋
I'm a Full-Stack
Developer.
As an experienced Full-Stack web developer, I'm focused on creating amazing digital experiences with code. I have expertise in both full-stack development and UI/UX design, and I pay high attention to detail to ensure everything looks and works perfectly in the final product.

About
While my primary focus has been on healthcare and fintech applications, those projects remain confidential due to strict data protection agreements and NDAs. The projects below represent my personal work aimed at continually enhancing my front-end skills and exploring creative technologies outside of regulated environments. Though different in nature from my professional work, they demonstrate the same attention to detail and user experience principles I apply in all my development.
Technologies under the belt:
Featured Project
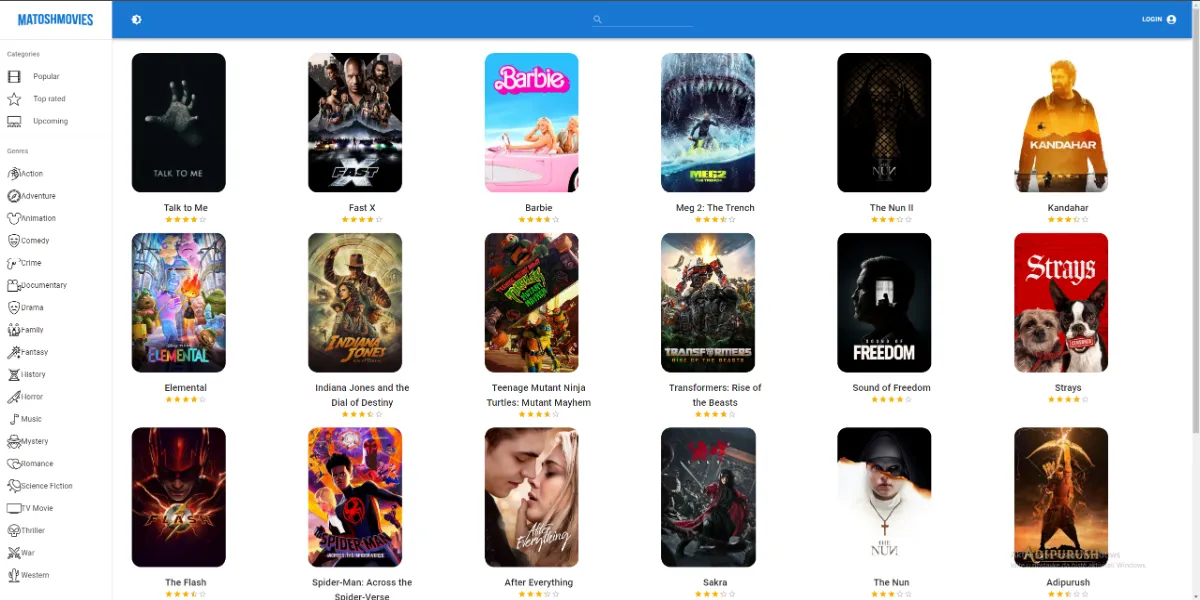
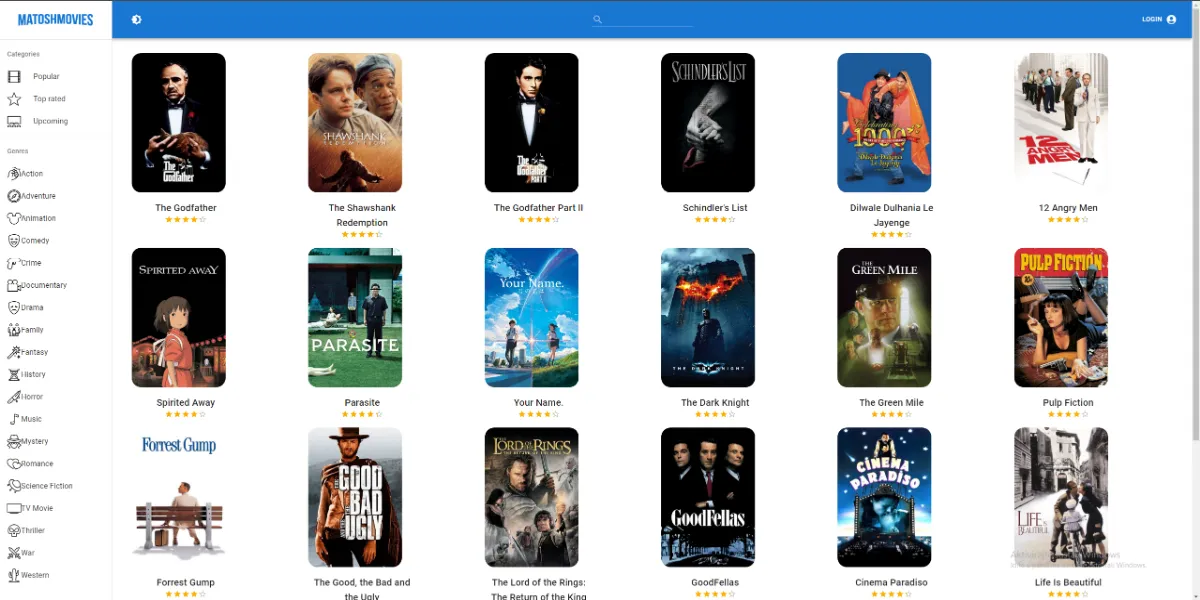
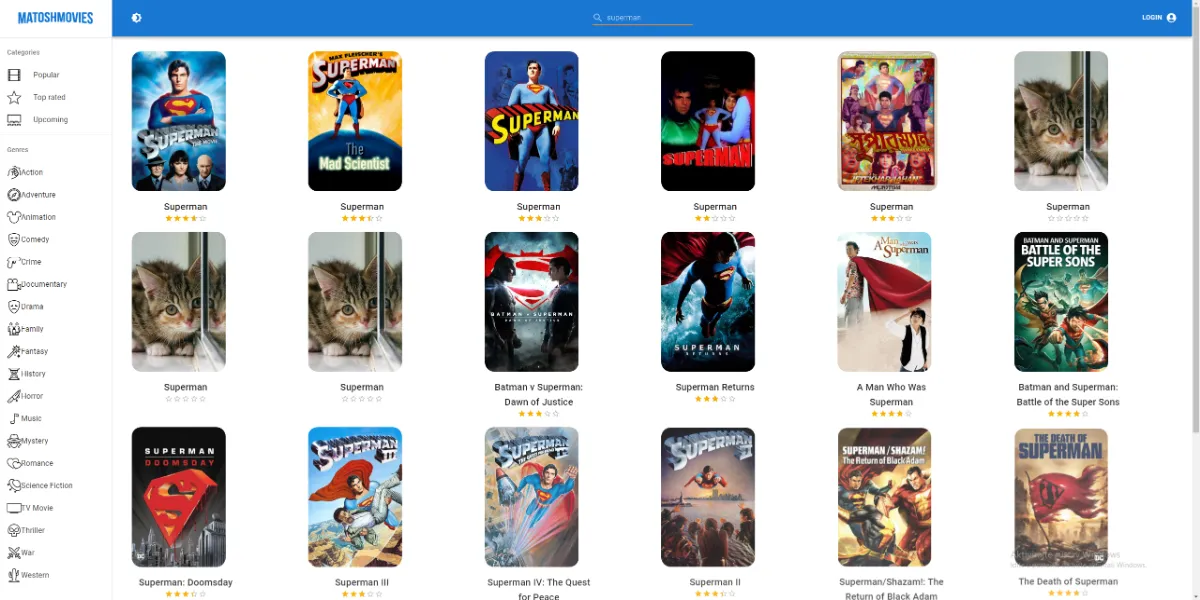
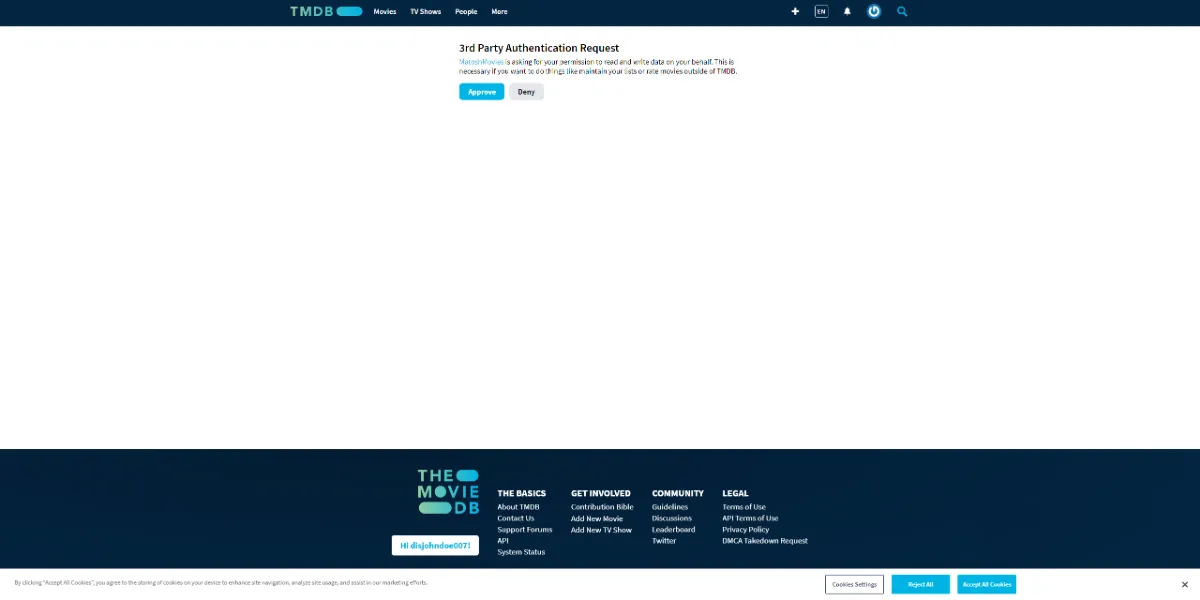
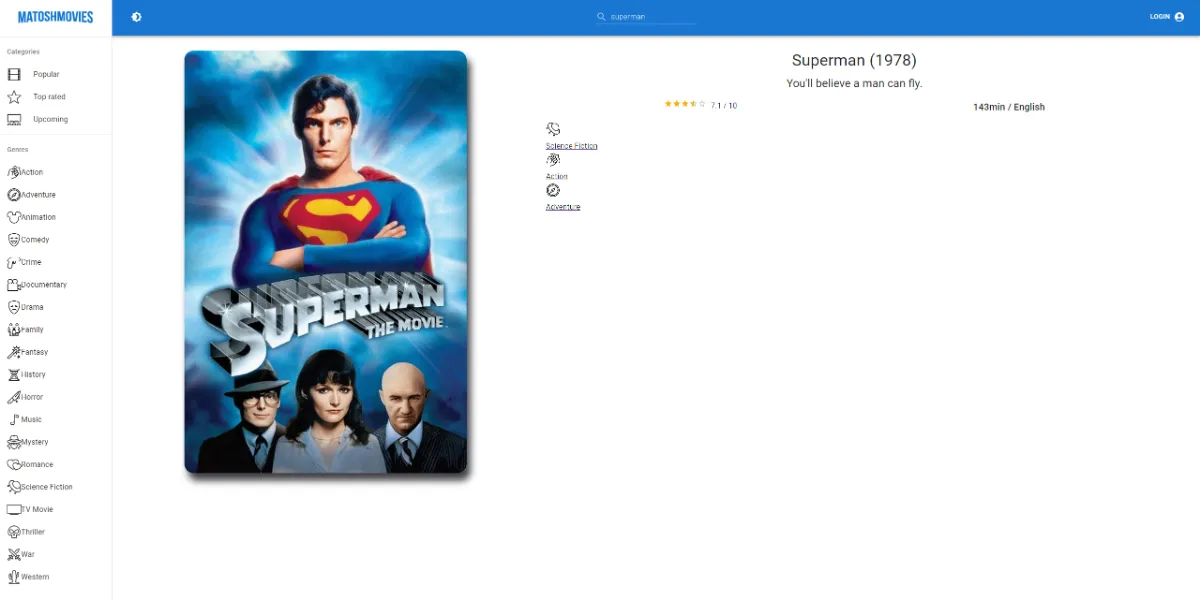
Fully responsive Movie database website made in React using Redux as a state container and IMDB.com API powered by Alan AI.
Tech Stack
Project type:
Fullstack-Jamstack
Timeline
March 2023 - Present

Projects
The following projects showcase my technical versatility and problem-solving approach across different domains. Each represents a unique set of challenges I've addressed through thoughtful architecture and clean implementation. From custom ERP systems to interactive e-commerce solutions and dynamic content platforms, these examples highlight my commitment to creating robust, user-focused applications that deliver tangible business value.

Bartels Conjar
Working across the full technology stack with a primary focus on backend development, I designed and implemented a custom ERP system for this client that streamlined their business operations.
The solution features advanced automation processes, secure data handling, and regulatory compliance while maintaining a user-friendly interface. My work significantly reduced manual processes and improved overall efficiency.
Visit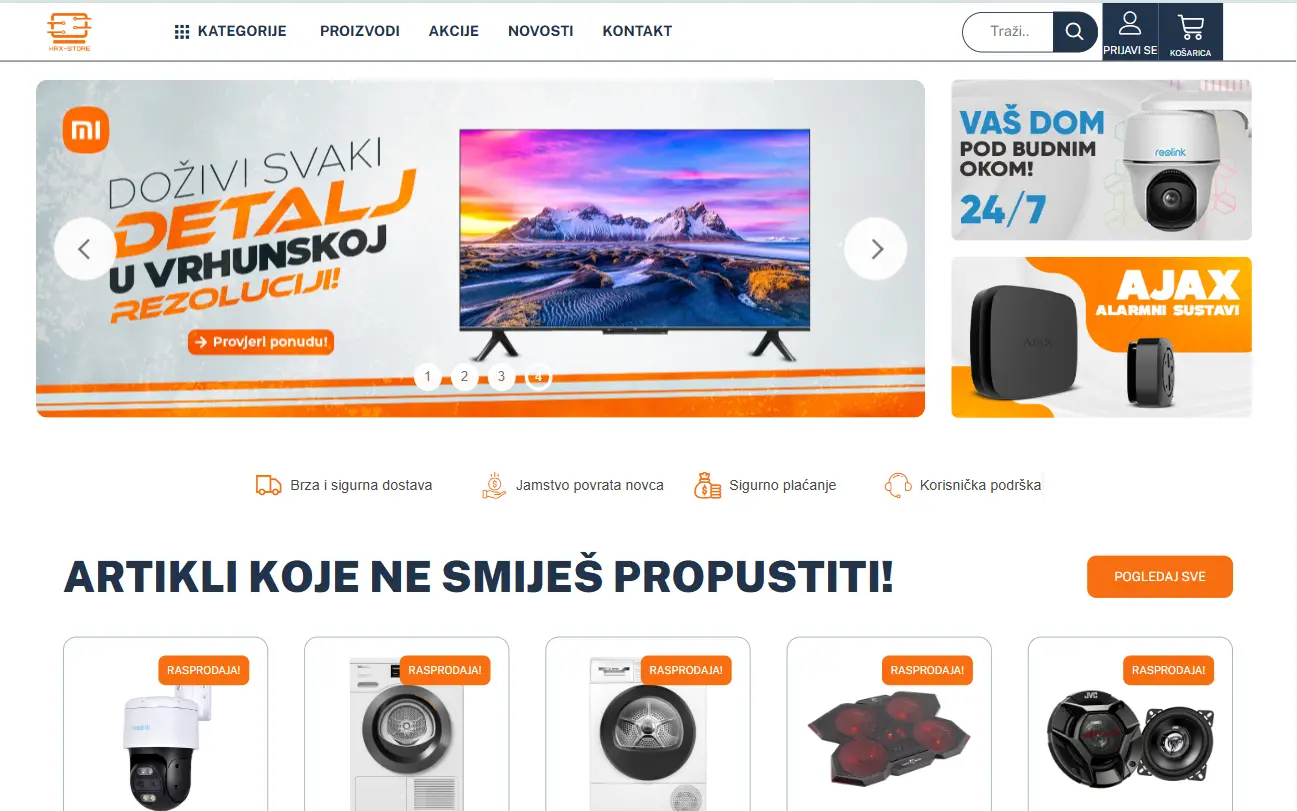
HRX Store
For this e-commerce project, I developed both front-end and back-end components with particular emphasis on creating an engaging user interface and shopping experience.
I built custom PHP, JavaScript, and CSS modules to enhance functionality while ensuring optimal performance. The implementation features responsive design, secure payment processing, and intuitive product navigation for an exceptional shopping experience.
Visit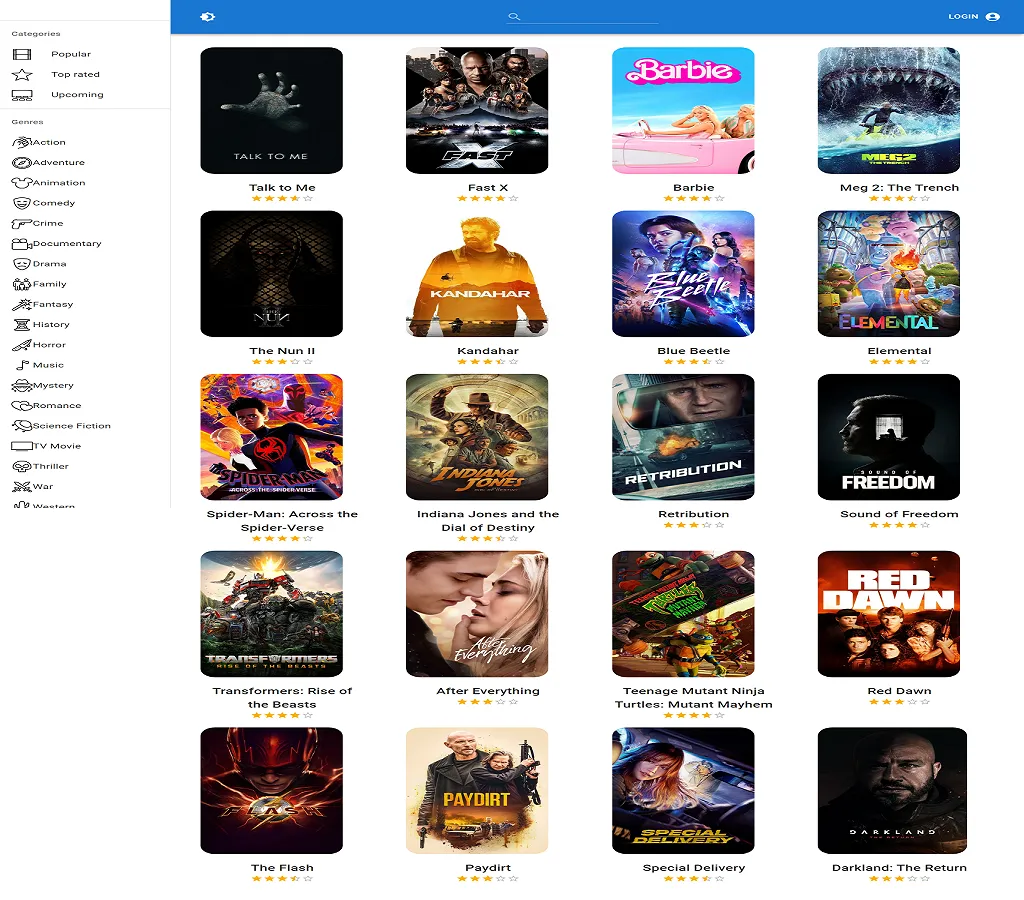
MatoshMovies
In the world of cinema, I embarked on an ambitious journey by building a movie website from the ground up using React as the foundation and Redux as the state manager.
This project was a labor of love, offering users an immersive and dynamic movie exploration experience. It's a testament to my dedication to crafting exceptional user interfaces and seamless interactions.
VisitGet In Touch
Hey there, whether you're kickstarting a new project, want to chat about some exciting business ventures, or simply fancy saying "zdravo" (that's "hi" in Croatian), my inbox is open and awaiting your messages! Drop me a line, and I'll reply to you quicker than you can say "ćevapčić." Let's make some digital magic happen!